
| 模型 | 進度 |
|---|---|
| VGG Net | 完成 |
| ResNet | 完成 |
| DensNet | 完成 |
| MobileNet | 此篇 |
| EfficientNet | 未完成 |
火雲邪神曾說:「天下武功,唯快不破」,
但那些又寬又深的網路,訓練時間和推論時間都極長,
我們要如何把它們放在手機等移動設備上呢?
所以科學家們開始反其道而行,
模型不再是以「大大大」為唯一目標,
有另外一個目標出現了:要小要快要輕。
而MobileNet就是著名的輕量化模型架構,
其論文開宗明義地說:
This paper describes an efficient network architecture
and a set of two hyper-parametersin order to build very small, low latency models
that can be easily matched to the design requirements for
mobile and embedded vision applications.
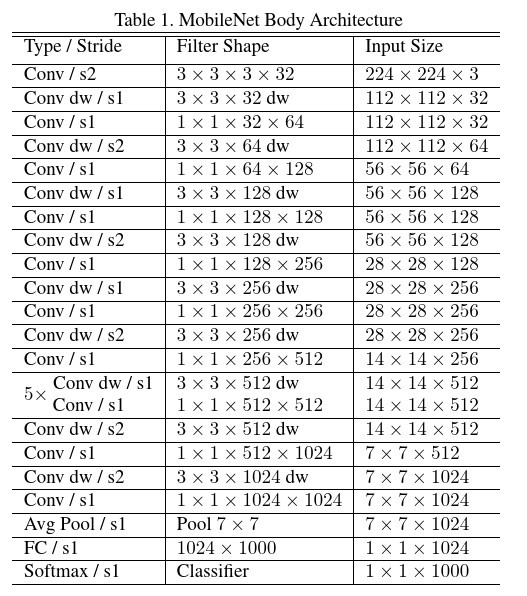
如下圖所示: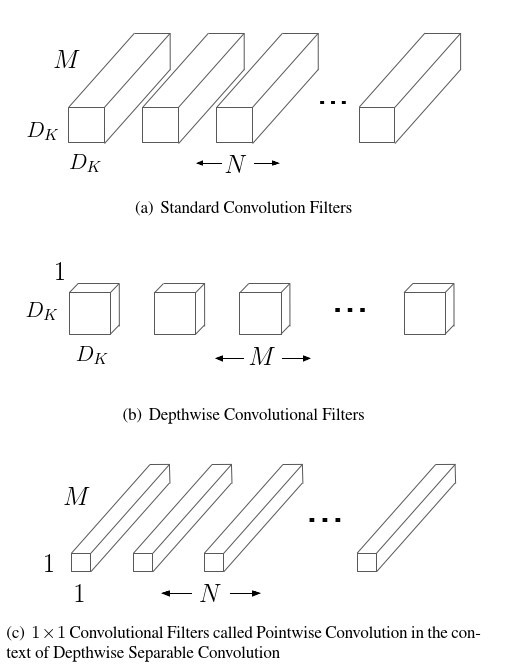
論文中也統計了各種類型的網路層所需參數量的比例: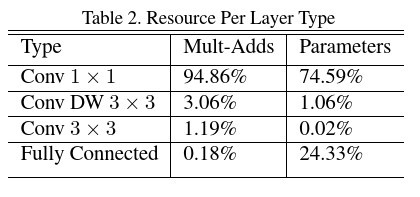
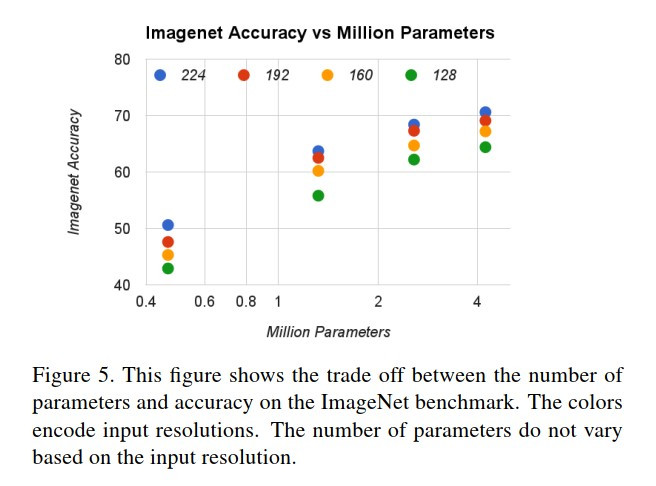
寬度乘子(α):把輸入/輸出通道數縮小,論文設置倍率是(0.25, 0.5, 0.75, 1.0)之一。
解析度乘子(ρ):減少輸入/輸出的解析度,論文設置解析度為(224, 192, 160, 128)之一。
論文在ImageNet上做實驗(α從左到右分別是0.25, 0.5, 0.75, 1.0)。
去比較這4種設置的模型準確率。
基本上只是證實了一件事:
在都是深度可分離卷積的設計下,又寬又胖的模型還是比較強。
但是模型基本上都很輕量化,最大的也僅有 4M 個參數。
而且解析度提高所增多的參數量較提高寬度來的少。
| 模型 | 參數量 |
|---|---|
| ResNet50 v1 | 23M |
| DensNet121 | 7M |
| MobileNet v1 | 3M |
| 模型 | 首發年分 | ImageNet test top-5 error |
|---|---|---|
| AlexNet | 2012 | 15.32% |
| VGG | 2014 | 6.8% |
| GoogleNet | 2014 | 6.67% |
| ResNet | 2015 | 3.57% |
| ResNeXt | 2016 | 3.03% |
| SENet | 2017 | 2.25% |
| MobileNet | 2017 | 10.5% |
那有沒有參數量和MobileNet差不多,
但是準確率能和state-of-the-art也差不多的架構呢?
有的!明天讓我來為你介紹...

 iThome鐵人賽
iThome鐵人賽